

1. Introduction
The emergence of Large Language Models (LLMs) like ChatGPT has ushered in a new era in text generation and AI advancements. While tools such as AutoGPT have aimed at task automation, their reliance on underlying DOM/HTML code poses challenges for desktop applications built on .NET/.SAP. The GPT-4 Vision (GPT-4v) API addresses this limitation by focusing on visual inputs, eliminating the need for HTML code.
1.1 The Challenge of Grounding
Although GPT-4v excels in image analysis, accurately identifying UI element locations remains a challenge. In response, a solution called "Grounding" has been introduced, involving pre-annotating images with tools like Segment-Anything (SAM) to simplify object identification for GPT-4v.

1.2 Adapting to the Usecase
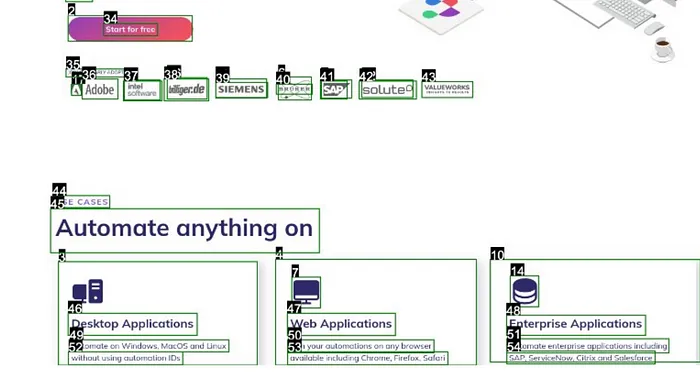
UI elements can be numbered for reference, streamlining the interaction process. For example, the "Start for Free" button might be associated with the number "34," enabling GPT-4v to provide instructions that can be translated into corresponding coordinates for controller actions.
2. Building Agents
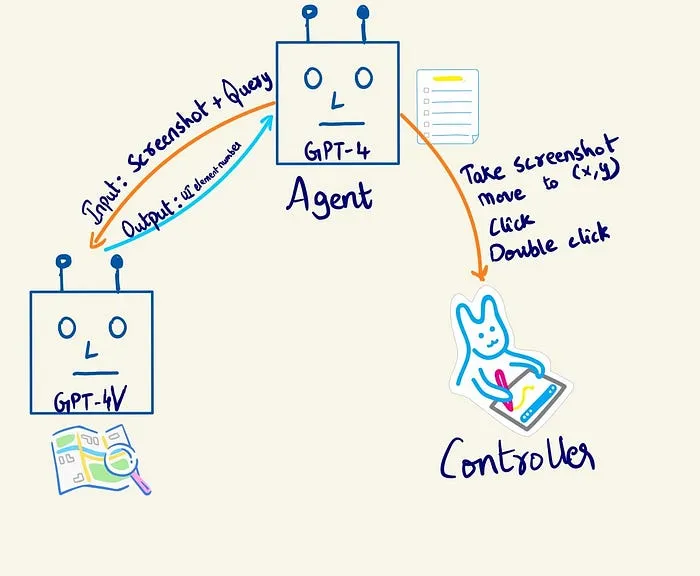
The envisioned product/tool aims to enter a goal/task and receive a set of actions to achieve it. The system operates in three sequential capabilities: goal breakdown, vision (image understanding), and system control. A GPT-4 text model acts as the orchestrator, interfacing with both GPT-4v and the device controller.
3. GPT-4V Integration: Visionary Function
GPT-4v serves as the visual interpreter, analyzing UI screenshots and identifying elements for interaction. An example function is provided to showcase how UI element identification is requested
def request_ui_element_gpt4v(base64_image, query, openai_api_key):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"temperature": 0.1,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"Hey, imagine that you are guiding me navigating the
UI elements in the provided image(s).
All the UI elements are numbered for reference.
The associated numbers are on top left of
corresponding bbox. For the prompt/query asked,
return the number associated to the target element
to perform the action. query: {query}"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 400
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
return response.json()4. Device Controller: The Interactive Core
The Controller class is pivotal, executing UI actions based on GPT-4v's guidance. Functions include moving the mouse, double-clicking, entering text, and capturing annotated screenshots, ensuring seamless interaction with the system:
- move_mouse(): Moves the cursor and performs clicks.
- double_click_at_location(): Executes double clicks at specified locations.
- enter_text_at_location(): Inputs text at a given location.
- take_screenshot(): Captures and annotates the current UI state.
The below class ensures seamless interaction with the system, acting based on GPT-4v's guidance.
import subprocess
import time
class Controller:
def __init__(self, window_name="Mozilla Firefox") -> None:
# Get the window ID (replace 'Window_Name' with your window's title)
self.window_name = window_name
self.get_window_id = ["xdotool", "search", "--name", self.window_name]
self.window_id = subprocess.check_output(self.get_window_id).strip()
def move_mouse(self, x, y, click=1):
# AI logic to determine the action (not shown)
action = {"x": x, "y": y, "click": click}
# Move the mouse and click within the window
if action["click"]:
subprocess.run(["xdotool", "mousemove", "--window", self.window_id, str(action["x"]), str(action["y"])])
subprocess.run(["xdotool", "click", "--window", self.window_id, "1"])
# wait before next action
time.sleep(2)
def double_click_at_location(self, x, y):
# Move the mouse to the specified location
subprocess.run(["xdotool", "mousemove", "--window", self.window_id, str(int(x)), str(int(y))])
# Double click
subprocess.run(["xdotool", "click", "--repeat", "1", "--window", self.window_id, "1"])
time.sleep(0.1)
subprocess.run(["xdotool", "click", "--repeat", "1", "--window", self.window_id, "1"])
def enter_text_at_location(self, text, x, y):
# Move the mouse to the specified location
subprocess.run(["xdotool", "mousemove", "--window", self.window_id, str(int(x)), str(int(y))])
# Click to focus at the location
subprocess.run(["xdotool", "click", "--window", self.window_id, "1"])
# Type the text
subprocess.run(["xdotool", "type", "--window", self.window_id, text])
def press_enter(self):
subprocess.run(["xdotool", "key", "--window", self.window_id, "Return"])
def take_screenshot(self):
# Take a screenshot
screenshot_command = ["import", "-window", self.window_id, "screenshot.png"]
subprocess.run(screenshot_command)
# Wait before next action
time.sleep(1)
self.image = Image.open("screenshot.png").convert("RGB")
self.aui_annotate()
return "screenshot taken with UI elements numbered at screenshot_annotated.png "
def aui_annotate(self):
assert os.path.exists("screenshot.png"), "Screenshot not taken"
self.raw_data = (request_image_annotation("screenshot.png", workspaceId, token)).json()
self.image_with_bboxes = draw_bboxes(self.image, self.raw_data)
self.image_with_bboxes.save("screenshot_annotated.png")
def extract_location_from_index(self, index):
bbox = extract_element_bbox([index], self.raw_data)
return [(bbox[0]+bbox[2])/2, (bbox[1]+bbox[3])/2]
def convert_image_to_base64(self):
return encode_image("screenshot_annotated.png")
def get_target_UIelement_number(self, query):
base64_image = self.convert_image_to_base64()
gpt_response = request_ui_element_gpt4v(base64_image, query)
gpt_response = gpt_response["choices"][0]["message"]["content"]
# Extract numbers from the GPT response
numbers = extract_numbers(gpt_response)
return numbers[0]
def analyze_ui_state(self, query):
base64_image = self.convert_image_to_base64()
gpt_response = analyze_ui_state_gpt4v(base64_image, query)
gpt_response = gpt_response["choices"][0]["message"]["content"]
# Extract numbers from the GPT response
numbers = extract_numbers(gpt_response)
return numbers[0]5. Orchestrator: The Strategic Planner
The Orchestrator, a GPT-4 text model, plans and executes tasks by leveraging the capabilities of the Device Controller and GPT-4v. Key components include the Planner (goal breakdown and action strategy), UserProxyAgent (communication facilitator), and Controller (UI action execution).
Key Components
- Planner: Breaks down goals and strategizes actions.
- UserProxyAgent: Facilitates communication between the planner and the controller.
- Controller: Executes actions within the UI.
Workflow Example
1. Initialization: The Orchestrator receives a task.
2. Planning: It outlines the necessary steps.
3. Execution: The Controller interacts with the UI, guided by the Orchestrator’s strategy.
4. Verification: The Orchestrator checks the outcomes and adjusts actions if needed.
We use AutoGen, an open source library that lets GPTs talk to each other, to implement the Automated UI controller. After giving each GPT its system message (or identity), we register the functions so that the GPT is aware of them and can call them when needed.
planner = autogen.AssistantAgent(
name="Planner",
system_message=
"""
You are the orchestrator that must achieve the given task.
You are given functions to handle the UI window.
Remember that you are given a UI window and you start the task by
taking a screenshot and take screenshot after each action.
For coding tasks, only use the functions you have been provided with.
Reply TERMINATE when the task is done.
Take a deep breath and think step-by-step
""",
llm_config=llm_config,
)
# create a UserProxyAgent instance named "user_proxy"
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"),
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
code_execution_config={"work_dir": "coding"},
llm_config=llm_config,
)
controller = Controller(window_name = "Mozilla Firefox")
# register the functions
user_proxy.register_function(
function_map={
"take_screenshot": controller.take_screenshot,
"move_mouse": controller.move_mouse,
"extract_location_from_index": controller.extract_location_from_index,
"convert_image_to_base64": controller.convert_image_to_base64,
"get_target_UIelement_number": controller.get_target_UIelement_number,
"enter_text_at_location": controller.enter_text_at_location,
"press_enter": controller.press_enter,
"double_click_at_location": controller.double_click_at_location,
"analyze_UI_image_state": controller.analyze_ui_state,
}
)
def start_agents(query):
user_proxy.initiate_chat(
planner,
message=f"Task is to: {query}. Check if the task is acheived by looking at the window. Don't quit immediately",
)6. Workflow on a Sample Task
The workflow involves the Orchestrator receiving a task, planning the necessary steps, executing actions through the Controller, and verifying outcomes. The article demonstrates a sample task—"click on the GitHub icon and click on the 'blogs' repository"—with a log history showcasing various executed functions.
Attached below is a log history, performing various actions. We can see that various functions are called and executed accordingly.

This article provides insight into the evolving automation landscape, anticipating remarkable developments built upon these technologies.

.png)
.png)
.png)
